摑寁偺榖乮俀乯丒丒丒丒丒暯嬒抣偲昗弨曃嵎偵偮偄偰
侾丏曣廤抍偲昗杮偺暯嬒抣偵偮偄偰
丂慜偺儁乕僕偱丄昗杮偐傜摼傜傟偨暯嬒抣乮倶僶乕乯偲昗弨曃嵎乮倱乯傪曣廤抍偺暯嬒抣乮兪乯偲昗弨曃嵎乮兟乯偲偟偰偟傑偊偲彂偒傑偟偨丅
側偤偦偺傛偆偵峫偊傞偺偐傪婰弎偟傑偡丅
偙偙偱壖掕偲偟偰師偺傛偆偵峫偊傑偡丅
壖掕侾乯
曣廤抍偼俆偱偁傞偲偟傑偡丅嵦偭偰偔傞昗杮偼俀偲偟傑偡丅倅亅score偱巊梡偝傟傞昗杮悢偼俀傛傝偼懡偄偲偍傕傢傟傑偡偑丄偙偺傛偆側壖掕偱峫偊傟偽丄慡惓忢擼偺恖偺悢偼俆柤偱偁傝丄偦偙傜傜柍嶌堊偵俀柤偺姵幰偝傫傪偲傝偩偟偰丄擼偺暯嬒抣偲昗弨曃嵎傪媮傔偨偙偲偲摨偠忦審偵側傝傑傑偡丅
壖掕俀乯
擼偺僺僋僙儖摉偨傝偺僇僂儞僩偼偦傟偩偗偐抦傝傑偣傫偑丄偙偙偱偼俆柤偺擼偺僇僂儞僩傪俀侽丄係侽丄俇侽丄俉侽丄侾侽偲偟傑偡丅
偙偺曣廤抍偐傜俀柤偺僇僂儞僩傪庢傝弌偟偰偒傑偡丅
埲忋偺壖掕偺傕偲偵曣廤抍偲昗杮偺暯嬒抣偲昗弨曃嵎偵偮偄偰峫偊偰傒傑偡丅
侾乯丂曣廤抍偺暯嬒抣偲昗弨曃嵎傪寁嶼偟傑偡丅
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂暯嬒抣乮兪乯亖乮俀侽亄係侽亄俇侽亄俉侽亄侾侽侽乯/俆丂亖丂俇侽
丂丂丂丂昗弨曃嵎乮兟乯亖俽俻俼乮乮俀侽亅俇侽乯丱俀亄乮係侽亅俇侽乯丱俀亄乮俇侽亅俇侽乯丱俀亄乮俉侽亅俇侽乯丱俀亄乮侾侽侽亅俇侽乯丱俀乯/俆乯丂亖丂俀俉丏俀俉丂丂丂
丂丂偲側傝傑偡丅
俀乯丂俀柤暘偺昗杮傪庢傝弌偟傑偡丅
丂丂丂侾侽捠傝偺庢傝弌偟僷僞乕儞偑偁傝傑偡丅
丂丂丂丂俀侽偲係侽偺俀偮傪庢傝弌偟偨偲偒傪乮俀侽丄係侽乯偲偟傑偡丅師偺僷僞乕儞偼乮俀侽丄俇侽乯丄師偼乮俀侽偲俉侽乯丒丒丒丒丒丒丒乮俉侽丄侾侽侽乯偲側傝傑偡丅
丂丂丂丂壓偵慡偰偺庢傝弌偟僷僞乕儞傪婰弎偟傑偡丅
丂丂丂丂乮俀侽丄係侽乯丂乮俀侽丄俇侽乯丂乮俀侽丄俉侽乯丂乮俀侽丄侾侽侽乯丂乮係侽丄俇侽乯丂乮係侽丄俉侽乯丂乮係侽丄侾侽侽乯丂乮俇侽丄俉侽乯丂乮俇侽丄侾侽侽乯丂乮俉侽丄侾侽侽乯
丂丂丂偙偙偱俀恖偺僇僂儞僩偐傜昗弨擼偺暯嬒抣偲昗弨曃嵎傪寛傔偰偄傞偺偱偡偐傜慻傒崌傢偣偺僷僞乕儞偱偺暯嬒傪挷傋偰傒傑偡丅
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俀侽丄係侽乯偺帪偺暯嬒偼乮俀侽亄係侽乯/俀丂亖俁侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俀侽丄俇侽乯丂丂丂丂丂丂丂丂丂乮俀侽亄俇侽乯/俀丂亖係侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俀侽丄俉侽乯丂丂丂丂丂丂丂丂丂乮俀侽亄俉侽乯/俀丂亖俆侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俀侽丄侾侽侽乯丂丂丂丂丂丂丂丂乮俀侽亄侾侽侽乯/俀亖俇侽丂
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮係侽丄俇侽乯丂丂丂丂丂丂丂丂丂乮係侽亄俇侽乯/俀丂亖俆侽丂丂丂丂丂丂丒丒丒丒丒丒丒暯嬒抣偺慻
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮係侽丄俉侽乯丂丂丂丂丂丂丂丂丂乮係侽亄俉侽乯/俀丂亖俇侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮係侽丄侾侽侽乯丂丂丂丂丂丂丂丂乮係侽亄侾侽侽乯/俀亖俈侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俇侽丄俉侽乯丂丂丂丂丂丂丂丂丂乮俇侽亄俉侽乯/俀丂亖俈侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俇侽丄侾侽侽乯丂丂丂丂丂丂丂丂乮俇侽亄侾侽侽乯/俀亖俉侽丂
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂乮俉侽丄侾侽侽乯丂丂丂丂丂丂丂丂乮俉侽亄侾侽侽乯/俀亖俋侽
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂
偙偺傛偆偵偟偰摼傜傟偨暯嬒偼俁侽乣俋侽傑偱偺抣傪偲傝丄庢傝弌偝傟偨儁傾乕偵傛傝暯嬒抣傕曄傢偭偰偒偰偟傑偄丄曣廤抍暯嬒俇侽偲偼堘偭偨抣偵側傝傑偡丅偠傖偁傕偟嬼慠偵乮俀侽丄係侽乯偑庢傝弌偝傟偨傜暯嬒偼俁侽偵側偭偰偟傑偄曣廤抍偺暯嬒俇侽偲偼偐偗棧傟偨抣偵側偭偰偟傑偭偰崲偭偨偙偲偵側傝傑偡丅
偙偙偱廔傢傜側偄偱傕偆彮偟墱怺偔傒偰偄偒傑偡丅
傕偆堦搙俀偮偺昗杮偺暯嬒抣傪婰弎偟傑偡丅
乮俁侽丄係侽丄俆侽丄俇侽丄俆侽丄俇侽丄俈侽丄俈侽丄俉侽丄俋侽乯偲側偭偰偄傑偡丅愭偺愢柧偱偼丄嬼慠偵乮俀侽丄係侽乯偺慻傒崌傢偣偑慖偽傟偰丄曣廤抍偺暯嬒抣俇侽偲偼偐偗棧傟偰偄傞偺偱崲偭偨偲婰弎偟傑偟偨丅偙傟偼丄庢傝弌偝傟偨慻傒崌傢偣偺暯嬒偑俁侽偵側偭偨偺偼嬼慠偺寢壥偱昁偢偦偆側傞偲偼尷傝傑偣傫丅
偙偙偱丄暘晍偲妋棪傪峫偊偰傒傑偟傚偆丅
俀偮偺庢傝弌偟偐偨偼侾侽慻偁傝傑偟偨丅偳偺慻傒崌傢偣偑庢傝弌偝傟傞偐偼晄柧偱偡丅偄傑偼暯嬒抣傪峫偊偰偄傑偡偐傜丄庢傝弌偝傟傞慻偺暯嬒抣偺暘晍傪偟傜傋偰傒傟偽丄暯嬒抣偺弌偐偨偺暘晍偑傢偐傝傑偡丅偙偺暯嬒抣偺暘晍偺拞偐傜丄巹偨偪偼侾慻傪慖傇偺偱偡偐傜暘晍傪抦傞偙偲偑廳梫偵側傝傑偡丅
忋偺暯嬒抣偺慻偺側偐偱丄俁侽偲側傞偺偼侾偮偱偡丅係侽傕侾偮偱偡丅俆侽偼俀偮偁傝傑偡丅俇侽偼俀偮丄俈侽傕俀偮丄俉侽偼侾偮丄俋侽傕侾偮偱偡丅
慡晹偱侾侽屄偺偁傝傑偟偨偐傜丄偙偺侾侽屄偐傜暯嬒抣偑俁侽偲側傞庢傝弌偝傟曽偼侾/侾侽偱偡丅係侽偲側傞偺傕侾/侾侽丄俆侽偲側傞偺偼俀/侾侽
俇侽偼俀/侾侽丄俈侽傕俀/侾侽丄俉侽偲側傞偺偼侾/侾侽丄俋侽傕侾/侾侽偲側傝傑偡丅
偦偺暘晍傪帵偟傑偡丅
丂
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂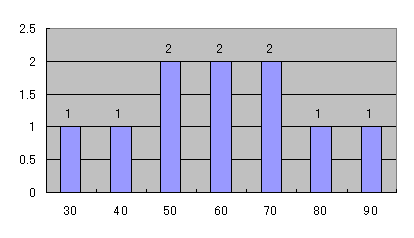
偙偺寢壥偐傜丄暯嬒抣偑俁侽偲側傞妋棪偼侾/侾侽偱慡懱偐傜傒傟偽侾侽亾偲側傝傑偡丅偟偐偟丄暯嬒抣俇侽偲側傞妋棫偼俀/侾侽乮俀侽亾乯偲側傝
傑偡偐傜丄曣廤抍偺暯嬒抣俇侽偲摨偠抣傪庢偭偰偔傞妋棪偼俀/侾侽偲側傝丄暯嬒抣俁侽偑慖偽傟傞妋棪傛傝崅偔側偭偰偄傑偡丅
偄傑偼丄俇侽偺傒傪峫偊傑偟偨偑丄曣廤抍偺暯嬒抣俇侽偵嬤偄抣乮俆侽丄俇侽丄俈侽乯偑庢傝弌偝傟傞妋棪傪峫偊傞偲丂俀/侾侽亄俀/侾侽亄俀/侾侽丂亖
俇/侾侽乮俇侽亾乯偑庢傝弌偝傟傞妋棪偲側傝傑偡丅
偟偨偑偭偰丄柍嶌堊偵庢傝弌偝傟傞俀偮偺僒儞僾儖偺暯嬒抣偺俇侽亾偼丄曣廤抍偺暯嬒抣偵嬤偄抣偲側傝傑偡偐傜丄妋棪偐傜傒偰傕暯嬒抣偑俁侽傗係侽丄俉侽丄俋侽偺俀偮偺僒儞僾儖偑庢傝弌偝傟傞偙偲偼傑傟偱偁傞偲峫偊傜傟傑偡丅
傑偨丄偙偺暘晍偐傜暯嬒抣乮倱乯傪寁嶼偟偰傒傑偡丅
丂丂丂丂丂丂丂丂乷乮俁侽亄係侽亄乮俆侽亊俀乯亄乮俇侽亊俀乯亄乮俈侽亊俀乯亄俉侽亄俋侽乯乸/侾侽丂亖俇侽侽/侾侽亖俇侽
偲側傝丄曣廤抍偺暯嬒抣乮兪乯亖俇侽偲昗杮偐傜媮傔偨暯嬒抣偺暘晍偺暯嬒偲偼堦抳偟偰偄傑偡丅
偙偺傛偆側偙偲偐傜
丂丂丂丂丂丂丂曣廤抍偺暯嬒抣偼乮兪乯昗杮偐傜庢傝弌偝傟偨暯嬒抣乮倱乯偲偟偰偟傑偍偆偲峫偊偰偄傞偺偱偟傚偆丅
丂
丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂丂 丂丂丂
丂丂丂 丂丂丂
丂丂丂